
目录

在学习socket网络连接的过程中,我们经常会看到以下这种代码:
cppint listenfd = socket();
bind(listenfd); //绑定主机
listen(listenfd); //设置监听上限
while (1) {
int connfd = accept(listenfd); //建立连接,获取fd
int n = read(connfd, buff); //读取数据
doSomeThing(buff); //处理数据
close(connfd); //关闭连接
}
当其运行成功后,会出现两个阻塞:
- accept
- read
accept阻塞意味着监听套接字处于监听状态,没有客户端程序进行连接。read阻塞意味着已经有客户端连接成功,但是没有数据需要我们读取。
1. 阻塞IO
当用户程序调用read时,会从用户态切到内核态,首先将接收到的数据放入内核缓冲区,再从内核缓冲区拷入用户缓冲区,从内核态切回用户态。
如果数据未到达网卡,或者未从网卡的缓冲区拷贝到内核缓冲区,这样便会阻塞;这里便是阻塞的IO,如下图所示:
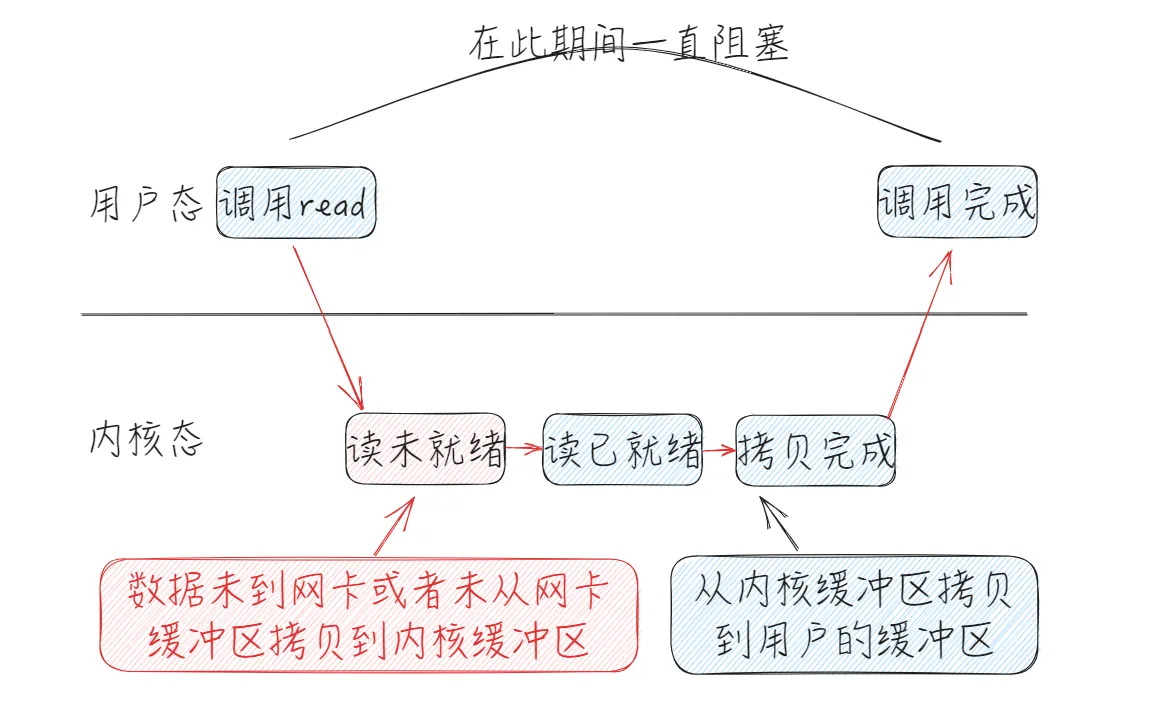
如果客户端一直没传数据,那么便会一直阻塞在read的调用上,socket连接也不会进行,数据处理也不会进行。
这是非常糟糕的一件事。如何解决这一问题?有以下做法
cppwhile(1) {
connfd = accept(listenfd); // 阻塞建立连接
pthread_create(doWork); // 创建一个新的线程
}
void doWork() {
int n = read(connfd, buf); // 阻塞读取数据
doSomeThing(buf); // 处理数据
close(connfd); // 关闭连接
}
此时,程序就不会发生 因为一个连接上没有数据传来而导致不能进行下一个连接 这种事情。
但是,这种做法仅仅是使用多线程理论使得read并没有阻塞在主线程上,而次线程仍会因read而阻塞等待,并非真正的非阻塞。
操作系统为我们提供的 read 函数仍然是阻塞的。所以真正的非阻塞 IO,不能是通过我们用户层的一点点小把戏实现,而是要恳请操作系统为我们提供一个非阻塞的 read 函数。
这便有了非阻塞的IO。
2. 非阻塞IO
非阻塞 read 函数的效果是,如果没有数据到达或到达网卡但并未拷贝到了内核缓冲区(即 读已就绪之前的所有状态),则立刻返回一个错误值(-1),而不是阻塞地等待。
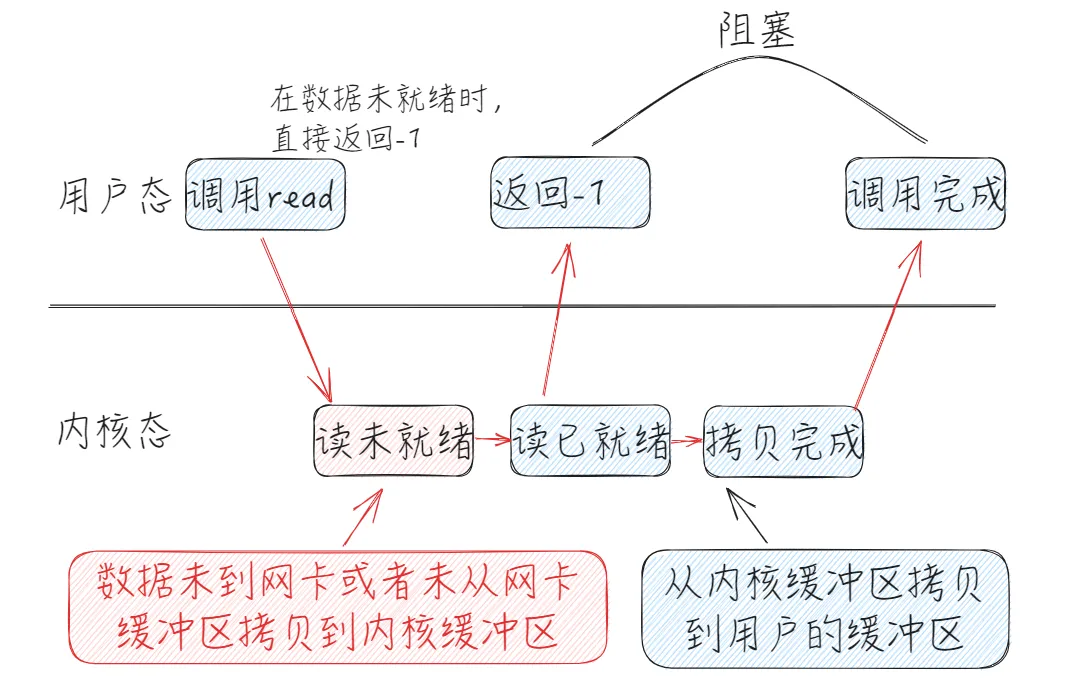
操作系统提供了这样的功能,只需要在调用 read 前,将文件描述符设置为非阻塞即可。
cppfcntl(connfd, F_SETFL, O_NONBLOCK);
int n = read(connfd, buffer) != SUCCESS);
这样才是真正的非阻塞IO。
非阻塞并非完全非阻塞
我们可以注意到的是,非阻塞IO并非完全的非阻塞,而是在读已就绪之前没有数据时是非阻塞的。
因此当我们讨论是使用阻塞还是非阻塞时应该看一看所处的状况下数据是否到达。
3. IO多路复用
在我们写socket网络程序时,需要考虑大量的客户端程序进行连接。
我们可以简单的设计一下:
- 有一个线程只接受tcp连接,并把连接到文件描述符存放到数组。
- 另外一个线程,对数组内的描述符执行非阻塞read操作。
这样的话,连接与接收数据便会互不影响,就像下面这段代码:
cppvector<int> fdlist; // 存放fd的容器
while (1) {
connfd = accept(listenfd); // 建立连接,获取fd
fdlist.add(connfd); // 添加到容器
}
...
while (1) {
for (fd <-- fdlist) {
if (read(fd) != -1) {
doSomeThing();
}
}
}
但是,就像我们使用多线程去修改阻塞时一样,这也只是我们用户层的把戏,表面上实现了较高的并发,但是在for循环下的read由于系统调用也将会大大消耗系统资源。
因此,我们还得恳请操作系统提供一个多路复用的方法。我们将一批文件描述符通过一次系统调用传给内核,由内核层去遍历,才能真正解决这个由于大量系统调用而引发的问题。
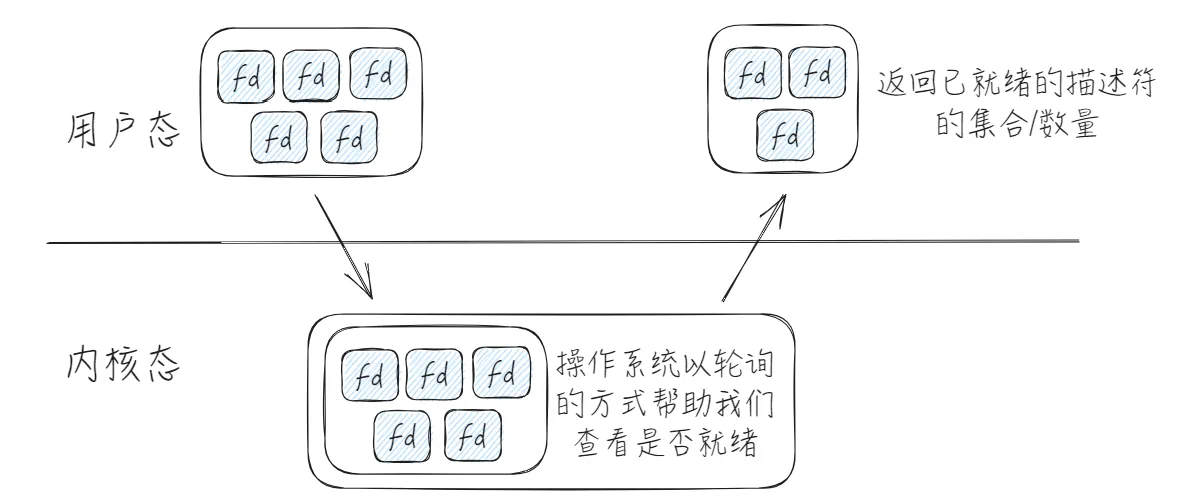
操作系统提供了三种IO多路复用的方法。
3.1 select
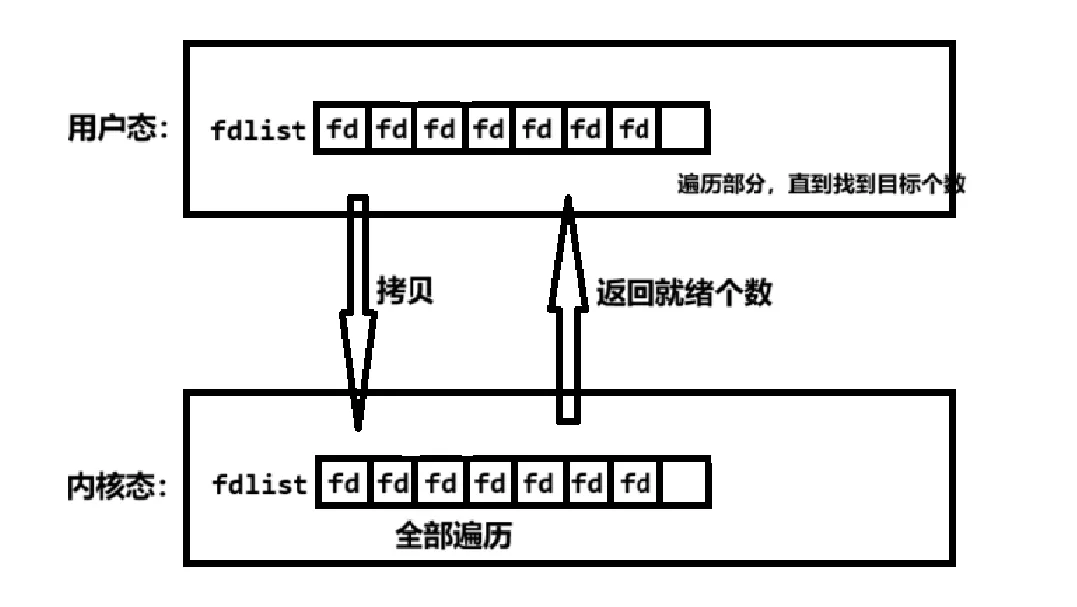
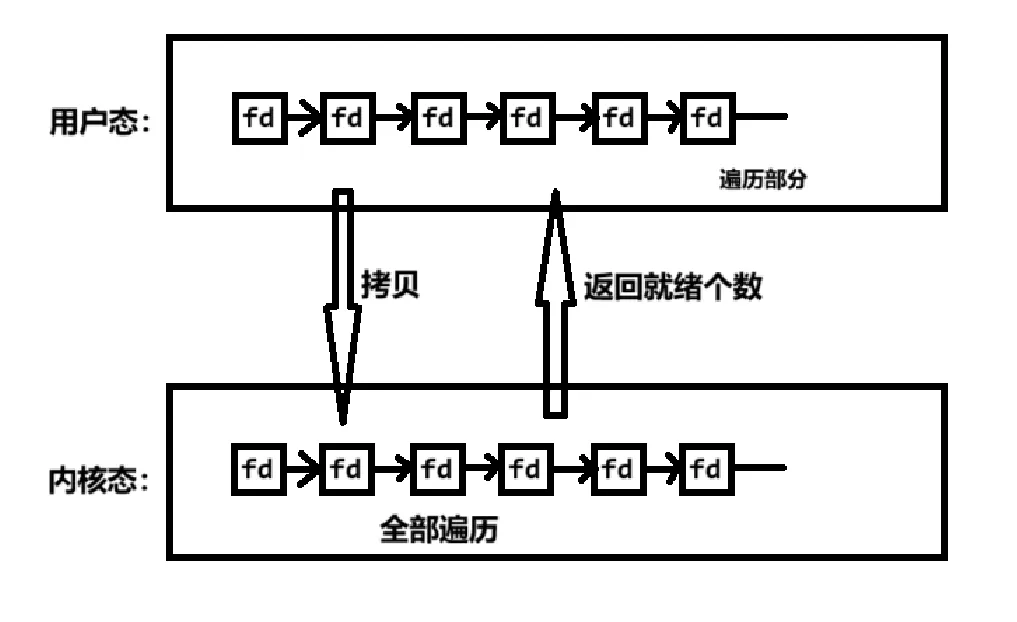
我们可以把一个文件描述符的数组发给操作系统,让操作系统去遍历,确定可以读写的描述符的数量,告诉我们,然后以较小的代价去找到这些描述符,并处理它们。select便是这样。
但是,值得注意的是:
- 数组存储文件描述符,那么数量是有限的。
- 调用select时必须传入数组,因此需从用户区域拷贝一个数组进内核区域,耗费大。
- 尽管只进行了一次系统调用,但是在内核中仍是以轮询的方式遍历数组,耗时耗力。
- 返回的仅仅是就绪的个数,用户态仍需再次遍历仅仅是遍历的少而已。但在某些特殊情况下,仍会全部遍历。
这便是select,系统提供的最初的多路复用。
3.2 poll
poll与select并没有本质区别,poll只是将select中的数组修改为链表,这样就会大大增加描述符的数量。
3.3 epoll
select与poll有很多的问题需要解决,因此系统为我们提供了一种非常强大的多路复用方法epoll。
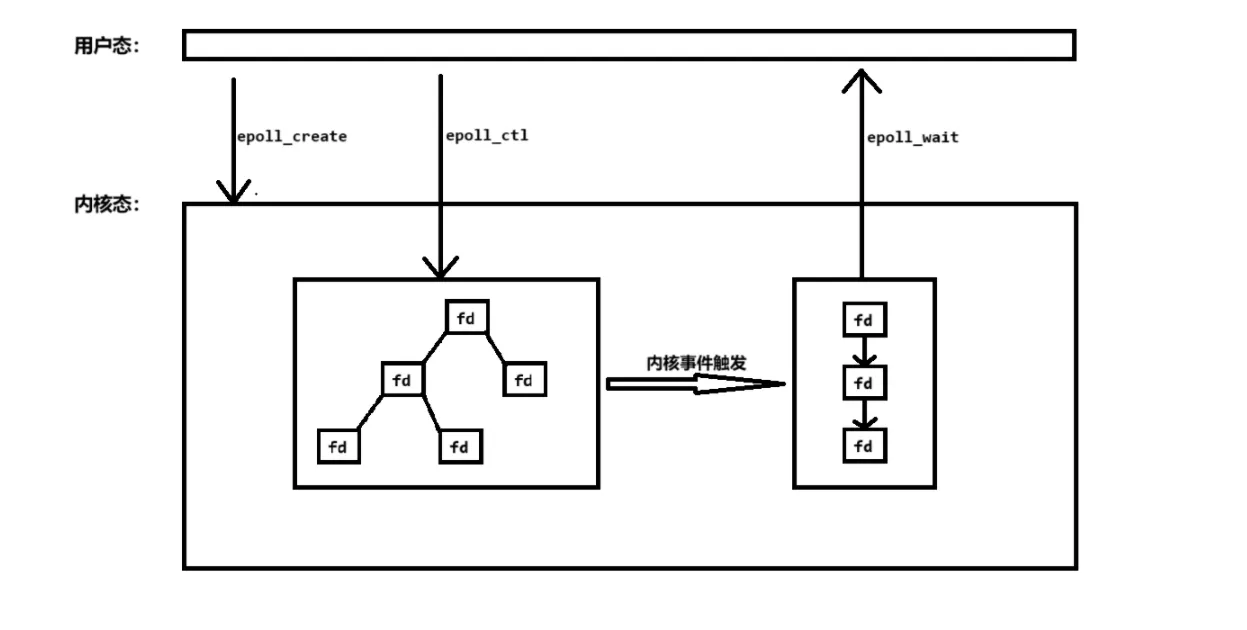
第一,不再使用数组或链表,而是使用红黑树,由于红黑树的特性,查找将会特别容易而且快速。
第二,用户态与内核态会共同对同一块内存进行映射,因此,免去了拷贝的消耗。
第三,epoll会返回已就绪的文件描述符的集合,因此不需要进行不必要的遍历,只对已就绪的进行操作即可。
3.3.1 epoll三大API
int epoll_create(int size); //构建一个epoll实例,并返回这个实例的句柄。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); //将被监听的文件描述符添加到事件表中,删除或修改表中的事件。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); //阻塞等待事件的发生,返回时间的数目,并将触发的事件写入events数组中
epoll监控多个文件描述符的I/O事件。epoll支持边缘触发(edge trigger,ET)或水平触发(level trigger,LT),通过epoll_wait等待I/O事件,如果当前没有可用的事件则阻塞调用线程。
3.3.2 epoll的简单使用
C//创建 epoll
int epfd = epoll_crete(1000);
//将 listen_fd 添加进 epoll 中
epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd,&listen_event);
while (1) {
//阻塞等待 epoll 中 的fd 触发
int active_cnt = epoll_wait(epfd, events, 1000, -1);
for (i = 0 ; i < active_cnt; i++) {
if (evnets[i].data.fd == listen_fd) {
//accept. 并且将新accept 的fd 加进epoll中.
}
else if (events[i].events & EPOLLIN) {
//对此fd 进行读操作
}
else if (events[i].events & EPOLLOUT) {
//对此fd 进行写操作
}
}
}
select和poll只支持LT工作模式,epoll的默认的工作模式是LT模式。
3.3.3 ET模式与LT模式
试想一下,发送端发送5个字符(HELLO),但在接受端读取时一次只能读一个。

当我们使用LT模式时,可能会出现以下情况:
H E L L O
为什么呢?那是因为在LT模式下,只要接收缓冲区未被读取完,便会通知,因此五行代表了五次事件。
但当使用ET模式时,就会是这样:
H
因为ET模式对于一个事件只有一次通知,但同时只读一个,因此只有H。
但是仍有一个问题,我们应该使用阻塞还是非阻塞?
如果在LT模式下,其实使用阻塞与非阻塞没太大的区别,因为LT模式是有数据才触发,没数据不触发,而阻塞与非阻塞IO的区别就在没数据的时候。
假如,在ET模式下使用阻塞IO,那么因为读小于接收,因此需要使用while(1)之类的循环操作去反复读取,但是当读完最后一个值之后,因为使用的阻塞IO,所以一定会因为读不到值而停止等待。但对于非阻塞IO,读不到值时会立即返回-1,根据错误码便可判断读完成。
我们可以看到的是,在接收缓冲区与读之间大小分配不合理才会出现了这么多不一样的情况。因此只要在此之间建立好一定的联系,使其能够合理分配,便可无忧。
总结
看到这里,我们便会发现一切的一切都源于阻塞的read这个系统调用,为了解决其长时间等待的问题,我们在用户态使用多线程去解决它。但是这个功能太重要了,因此系统提供了一种非阻塞的read,此时我们便可以直接使用非阻塞read。
当我们有多个文件描述符需读取数据时,就需要遍历,当用户态遍历的文件描述符越来越多时,相当于在 while 循环里进行了越来越多的系统调用,这是糟糕的,因此系统又为我们提供了尽量少切换状态便可遍历的功能,那便是IO 多路复用。
本文作者:流浪的将军
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!